
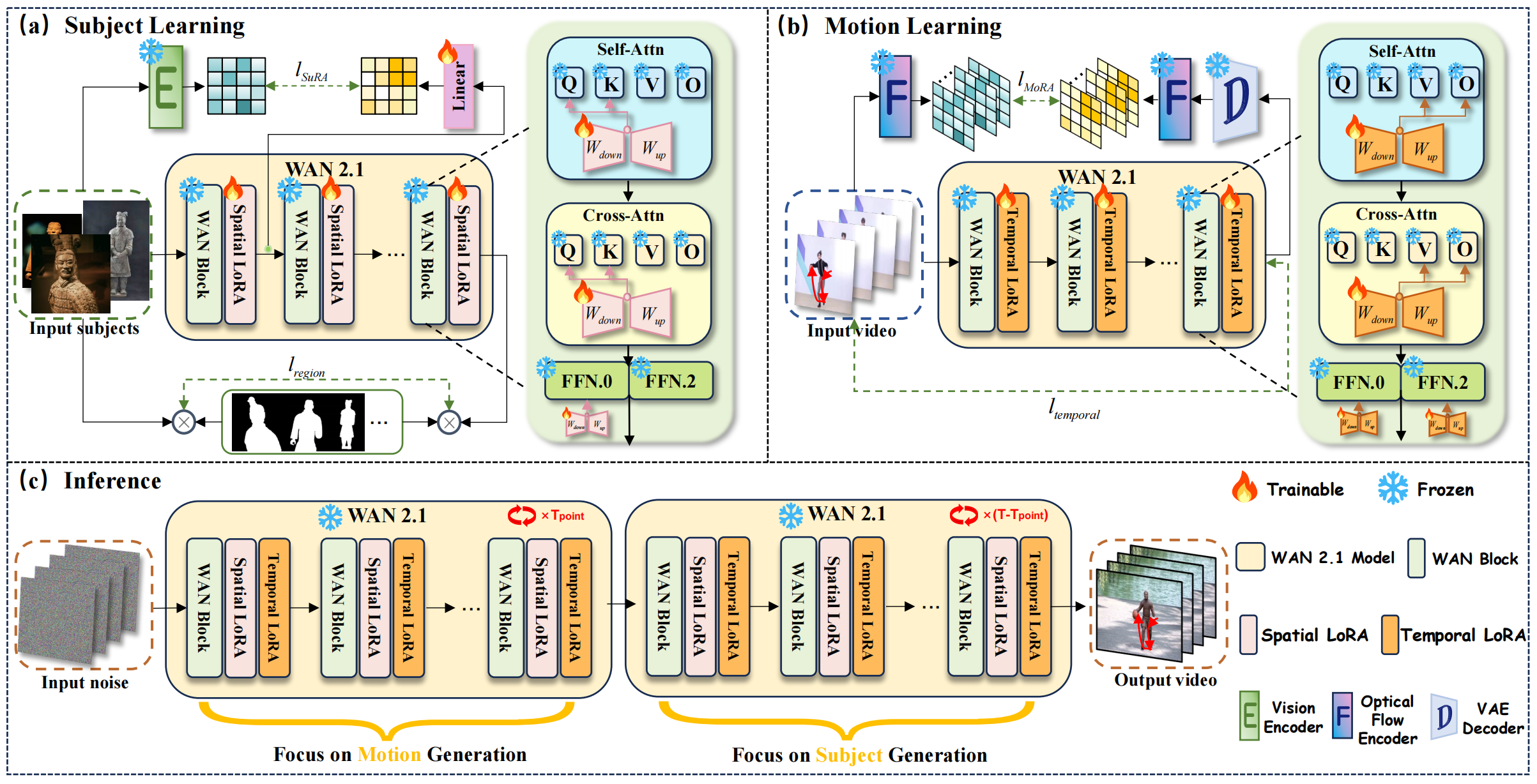
Customized video generation aims to produce videos that faithfully preserve the subject's appearance from reference images while maintaining temporally consistent motion from reference videos. Existing methods still struggle to ensure both subject appearance similarity and motion pattern consistency. To address this, we propose SMRABooth, which leverages the DINO encoder and optical flow encoder to provide object-level subject appearance and motion representations. These representations are aligned with the model during the LoRA fine-tuning process. Our approach is structured in three core stages: Firstly, we exploit spatial representations extracted from reference images with a self-supervised vision encoder to guide spatial alignment, enabling the model to capture the subject’s overall structure and to improve high-level semantic consistency. Secondly, we utilize temporal representations of optical flow from reference videos to capture structurally coherent and object-level motion trajectories independent of appearance. Moreover, we propose a subject-motion association decoupling strategy that applies sparse LoRAs injection across both locations and timing, effectively reducing interference between subject and motion LoRAs. Extensive experiments show that SMRABooth excels in subject and motion customization, maintaining consistent subject appearance and motion patterns, proving its effectiveness in controllable text-to-video generation.
You can generate videos flexibly with any subject and any motion.
All the generated videos are the resolution of 832 × 480.

"dog"
"a person is riding a bike"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"A dog is riding a bike around marble columns, with smooth stone floors echoing the sound of its wheels."

"orange Porsche car"
"a boat is traveling"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"An orange Porsche car is traveling along a wide highway on the Moon, with gray lunar dust rising behind, distant craters surrounding the road, and the Earth shining brightly in the dark sky"

"plushie panda"
"a bus is running"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"A plushie panda is running through a bamboo forest, with tall green stalks rising overhead, patches of fallen leaves on the ground."

"cat"
"a car is running"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"A cat is running along a garden path, surrounded by colorful flower beds, neatly trimmed hedges, and soft sunlight filtering through the trees."

"terracotta warrior"
"a person is lifting weights"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"A terracotta warrior is lifting weights in an ancient courtyard, with red lanterns hanging from the eaves, intricate stone carvings on the walls."

"cat"
"a woman is playing flute"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"A cat is playing the flute under a sprawling oak tree, with golden autumn leaves scattered across the ground."

"dog"
"a boy is skateboarding"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"A dog is skateboarding through an open-air market, dodging fruit stands and weaving between busy shoppers."

"terracotta warrior"
"a person is dribbing a basketball"
WAN2.1
WAN2.1+LoRAs
DualReal
ICCV'25
SMRABooth
(based on WAN)
"A terracotta warrior is dribbling a basketball on a riverside promenade, with flat paving blocks and willow shadows on the path."
"A cat is skateboarding on a rainy sidewalk, with puddles splashing as it glides and colorful umbrellas in the background."
"A dog is skateboarding across a windy desert plateau, with sand kicking up behind it and distant mountains on the horizon."
"A plushie teddy bear is skateboarding through a cozy kitchen, jumping over spilled flour and gliding past stacks of cookies on the counter."
"A terracotta warrior is skateboarding through a bustling ancient marketplace, dodging merchants and carts loaded with goods."
"A cat is playing piano on a cozy windowsill, with soft sunlight streaming through the glass and potted plants gently swaying in the breeze."
"A dog is playing piano in a bustling city square, with people walking by, tall skyscrapers in the background, and streetlights glowing as twilight sets in."
"A dog is playing piano in a quiet park under a canopy of cherry blossoms, with petals gently falling and a wooden bench nearby."
"A cat is playing piano on a rocky cliff near the ocean, with waves crashing below and seagulls soaring in the clear blue sky."
"A plushie bear is riding a bike across a city square at dusk, with fountains spraying lightly and shop lights flickering on."
"A dog is riding a bike along a sandy beach track, with waves rolling nearby and gulls circling in the distance."
"A dog is riding a bike on a rooftop court, with low fences around and the skyline visible under the night sky."
"A plushie sloth is riding a bike on a snowy path, with footprints trailing behind and pale aurora colors above."
"A cat is running along a garden path, with trimmed hedges on both sides and small stones scattered underfoot."
"A plushie sloth is running on a snowy lane, with frosty branches overhead and smoke rising from chimneys nearby."
"An orange Porsche car is running along a coastal highway curve, with cliffs dropping steeply and waves crashing below."
"A dog is running under a canopy of trees in a forest park, with sunlight dappling the ground, a small stream flowing nearby, and ferns growing along the trail."
You can generate videos flexibly with any subject and any motion.
All the generated videos are the resolution of 384 × 384.

"toy bear"
"a person is playing golf"
DreamVideo
CVPR'24
MotionBooth
NeurIPS'24 Spotlight
MotionDirector
ECCV'24 Oral
SMRABooth
(based on ZeroScope)
"a toy bear is playing golf"

"car"
"a car is running"
DreamVideo
CVPR'24
MotionBooth
NeurIPS'24 Spotlight
MotionDirector
ECCV'24 Oral
SMRABooth
(based on ZeroScope)
"a car is driving on the snow road"

"plushie wolf"
"a car is running"
DreamVideo
CVPR'24
MotionBooth
NeurIPS'24 Spotlight
MotionDirector
ECCV'24 Oral
SMRABooth
(based on ZeroScope)
"a plushie wolf is running in the forest"

"dog"
"a person is playing guitar"
DreamVideo
CVPR'24
MotionBooth
NeurIPS'24 Spotlight
MotionDirector
ECCV'24 Oral
SMRABooth
(based on ZeroScope)
"a dog is playing guitar in the room"

"dog"
"a person is riding a bike"
DreamVideo
CVPR'24
MotionBooth
NeurIPS'24 Spotlight
MotionDirector
ECCV'24 Oral
SMRABooth
(based on ZeroScope)
"a dog is riding a bike on the road"
"dog"
"a car is running"
DreamVideo
CVPR'24
MotionBooth
NeurIPS'24 Spotlight
MotionDirector
ECCV'24 Oral
SMRABooth
(based on ZeroScope)
"a dog is running in a park"

"dog"
"a car is running"
DreamVideo
CVPR'24
MotionBooth
NeurIPS'24 Spotlight
MotionDirector
ECCV'24 Oral
SMRABooth
(based on ZeroScope)
"a dog is running in a yard"
More diverse video generation results with different subjects and motions.
"a toy duck is swimming on the water"
"a toy robot is playing guitar in the room"
"a toy robot is playing golf in a garden"
"a toy car is running on the snowy road"
"a dog is riding a bike on the beach"
"a happysad is playing guitar in the room"
"a plushie panda is rolling in the forest"
"a plushie wolf is playing guitar in the room"
"a cat is playing piano in the room"
"a dog is playing piano on a beach"
"a plushie teddybear is playing piano in the room"
"a toy bear is playing piano in the room"
"a dog is lifting weights in a park"
"a dog is lifting weights on the grass"
"a plushie panda is lifting weights in a park"
"a toy bear is lifting weights in a garden"
You can generate videos flexibly with only subject control.
All the generated videos are the resolution of 832 × 480.

A plushie bear is dancing joyfully in the middle of Times Square at night, surrounded by massive glowing billboards, flashing advertisements, vibrant city lights reflecting on the wet pavement, and a lively crowd capturing the moment with excitement.

A cat is running swiftly on the surface of the moon, leaving tiny paw prints in the silver dust under the vast starry sky, with Earth glowing brightly in the distance and the barren lunar landscape stretching endlessly around.

A dog is walking calmly under the glowing aurora in the night sky, with shimmering green and purple lights dancing above, snow-covered ground reflecting the colors, and a serene silence surrounding the scene.

A dog is running playfully along the beach, with waves splashing near its paws, golden sand flying behind, and the sunset painting the horizon in warm colors.

A dog is swimming energetically in a clear blue lake, creating splashes in the water, with reflections of the sky and surrounding trees shimmering on the surface.

A dog is walking slowly in a supermarket, surrounded by tall shelves filled with colorful products, bright fluorescent lights overhead, and neatly arranged aisles stretching into the distance.

A cat is running in the park, with soft grass under its paws, colorful flowers around, tall trees casting shadows, and warm sunlight streaming through the leaves.

A dog is running under the stars, with the night sky full of constellations, a gentle breeze brushing its fur, and the quiet city lights glowing faintly below.

A plushie panda is running on the Great Wall of China, with the ancient stone bricks beneath it, winding walls stretching over green mountains, and the horizon glowing under the sun.

A cartoon demon is running across a volcanic landscape, with streams of lava glowing red and dark smoke rising into the sky.

A terracotta_warrior is rowing a boat on a calm river, with willows hanging low and reflections shimmering on the water.

A man is riding a motorbike along a coastal cliff road, with ocean waves crashing far below and the horizon glowing in the sunset.

A plushie happysad is swimming around the vibrant coral reef, its soft, colorful body surrounded by swaying seaweed, bright corals, and curious fish gliding by.

A plushie tortoise is swimming around the vibrant coral reef, its soft, colorful body surrounded by swaying seaweed, bright corals, and curious fish gliding by.

A orange Porsche car is speeding down a coastal highway, with ocean waves crashing against the cliffs and the sunset glowing on the horizon.

A white Lamborghini car is running under the neon lights of a bustling city, with skyscrapers towering overhead and colorful reflections glowing on the wet street.
You can generate videos flexibly with only motion control.
All the generated videos are the resolution of 832 × 480.
"a man is lifting weights"
A robot is lifting weights in a futuristic gym, with glowing panels on the walls and advanced machines humming nearby.
A soldier is lifting weights on a military base, with tents and vehicles in the background under a clear sky.
"a person is playing basketball"
A sleek alien with glowing purple skin and bioluminescent patterns is dribbling a bright green basketball in the middle of a mystical jungle, surrounded by oversized glowing plants and floating spores emitting soft light.
A humanoid robot with a sleek metallic body is dribbling basketball on a futuristic court,surrounded by holographic audience displays and neon-lit surroundings.
"a car is running"
A cyberpunk motorcycle with glowing neon accents is running through a rainy,high-tech cityscape,its lights reflecting on the wet pavement as holographic billboards illuminate the towering skyscrapers.
A heavily armored tank with wide tracks is running across a vast desert,its wide tracks kicking up clouds of sand,with majestic pyramids visible in the background under a bright, sunny sky.
"a bus is traveling"
A futuristic hover train with smooth,sleek designs is traveling acrossa sprawling desert canyon,with towering red cliffs and a deep blue sky stretching endlessly above.
The wooden boat with a small cabin is traveling across the lake, leaving gentle ripples behind as seagulls fly over head and the surrounding mountains reflect clearly on the calm water.
"a girl is playing the piano"
A woman is playing the piano under a cherry blossom tree at night,with petals falling softly and a full moon casting a serene glow over the scene.
A monk is playing the piano in a quiet temple hall, with candles flickering softly and ancient murals on the walls.
"a car is running"
A rugged Mars rover with robotic arms and thick treads is maneuvering across the jagged surface of an alien planet, with strange rock formations and a binary star system glowing in the sky.
A heavily armored tank with wide tracks and long cannon is running across the moon rugged, dusty surface, kicking up lunar dust as Earth glows vividly in the dark, star-filled sky.
"a girl is playing the flute"
A wizard in a flowing purple robe is playing the flute at the peak of a snowy mountain, surrounded by swirling clouds and lightning crackling in the distance.
A street musician in casual clothes is playing the flute in a busy city square, with people walking by and towering skyscrapers in the background.